Why Your RAG Pipeline Needs a Lineage Graph Before It Needs a Better Embedder
Modern RAG pipelines depend heavily on embeddings, vector databases, and retrieval optimization. However, many teams overlook a more fundamental problem: understanding where their data originates, how it changes, and which downstream systems depend on it.
Without proper lineage visibility, even highly optimized retrieval systems can generate unreliable responses from outdated or untrusted data sources.
Why Data Lineage Matters in RAG Systems
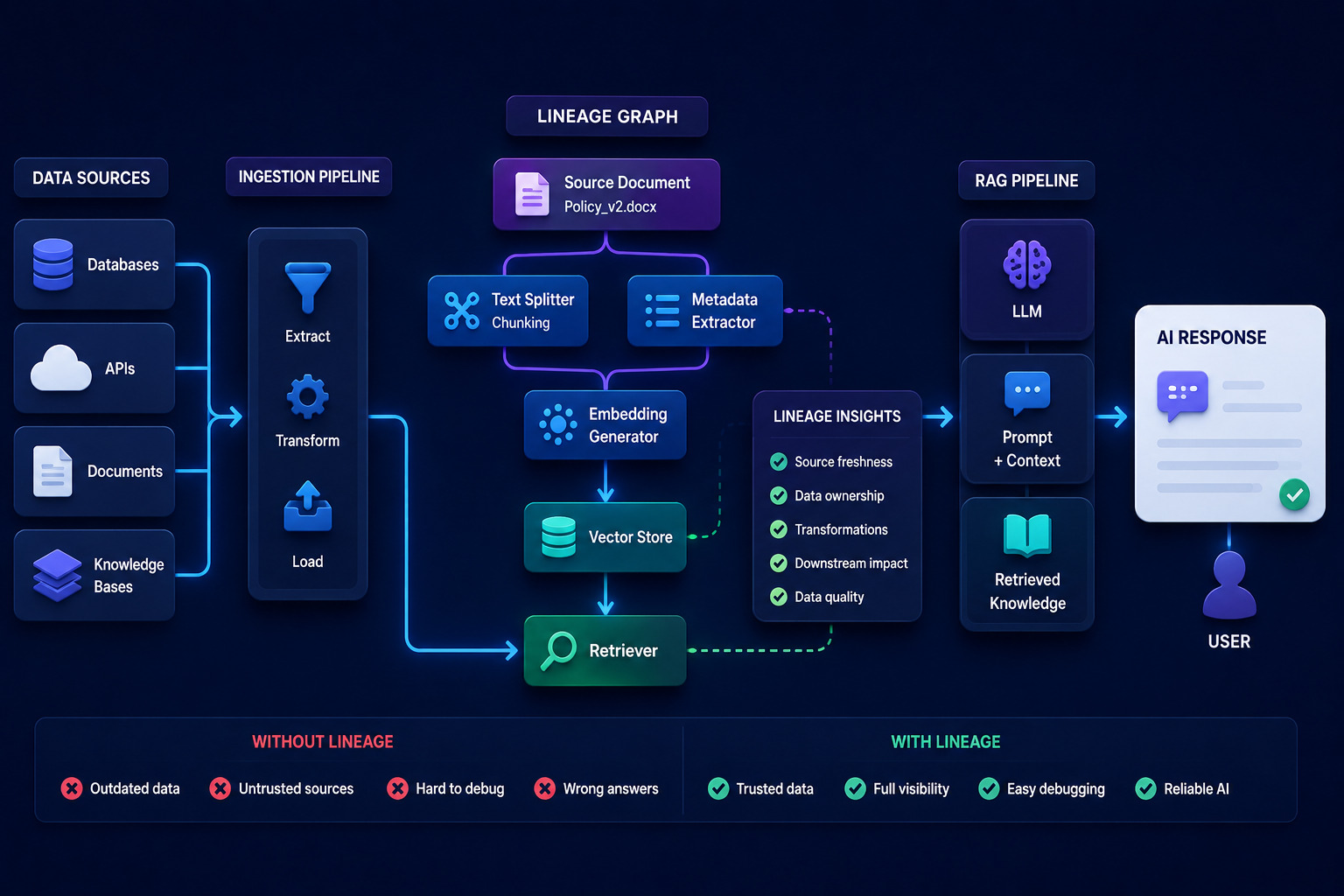
RAG pipelines continuously ingest data from multiple systems including databases, APIs, documents, and internal knowledge platforms. As these sources evolve, tracking transformations and dependencies becomes increasingly difficult.
Without lineage tracking, teams often struggle to:
- Identify outdated knowledge sources
- Trace incorrect AI-generated responses
- Understand downstream data dependencies
- Monitor trust and governance risks
- Debug retrieval inconsistencies
This creates operational blind spots inside production AI systems.
The Problem With Focusing Only on Embeddings
Many organizations attempt to improve RAG quality by experimenting with larger embedding models or more advanced vector search strategies.
While embeddings improve retrieval performance, they cannot solve:
- Broken upstream data pipelines
- Inconsistent source updates
- Duplicate document ingestion
- Missing governance controls
- Unverified knowledge sources
A better embedder cannot fix unreliable data foundations.
Building Lineage-Aware AI Pipelines
Lineage graphs provide visibility into how data flows across ingestion pipelines, transformation layers, vector stores, and downstream AI applications.
Modern lineage-aware architectures help teams:
- Track document origins
- Detect stale knowledge sources
- Improve observability across AI systems
- Validate retrieval trustworthiness
- Simplify debugging and incident response
This creates more reliable and explainable AI infrastructure.
Example Use Case
For example, if an outdated policy document remains inside a vector database after a compliance update, an AI assistant may continue generating inaccurate responses based on obsolete information.
A lineage-aware RAG pipeline can quickly identify where the outdated document originated, when it was updated, and which downstream systems consumed it.
Building Trustworthy RAG Infrastructure
As enterprise AI systems scale, data lineage becomes increasingly critical for maintaining trust, governance, and operational reliability.
Teams that invest in lineage visibility early build more resilient RAG pipelines and reduce the risk of silent failures across production AI environments.